It is time for the second monthly post about my GSoC project which is to implement an automated ranking system for OWASP - OWTF.
Today I am going to show the last modification I have done on the classful plugin system. Then I present my new library that aims to be the solution for my project: PTP and I finish with the new OWTF's plugin report template that I have created.
Classful Plugin System, the end of the road
During the first month of the GSoC, which aims for the students and their
mentors to know each other, I worked on a more efficient way to declare new
attributes for a plugin.
During my work, I took a deeper look on how the current system was working and
I thought I could implement a better one.
Long story short, I ended up writing a completely different system, a classful
one.
Each class has its own goal like running a shell command (i.e. an
ActivePlugin) or retrieve some data from the database (i.e. a
PassivePlugin).
In the previous post, I shown some snippets of the current work and I think that now the system is complete.
What changed
I simplified the previous hierarchy but merging the AbstractRunCommandPlugin
and the ActivePlugin. I thought that only an active plugin would need to run
a shell command (like running Arachni for
instance) hence the AbstractRunCommandPlugin was an extra layer with no
actual meaning.
I also finished implementing the other classes like PassivePlugin,
SemiPassivePlugin, GrepPlugin and ExternalPlugin classes.
Automatically retrieve a class from a module
After declaring all of the classes, I was able to rewrite the plugins and then I had to modify OWTF in order to run the new plugins.
I already have updated OWTF plugin manager in order to dynamically loads each
plugin using the imp module.
Now, I had to modify it in order automatically retrieve the new plugin class
declaration and it was a little bit tricky.
Looking over the Internet, I have found several topics describing the process
(or at least a similar process). I have found the
inspect module for
instance, some workaround using the
dir() function.
After a couple of tests, I found that using a simple __dict__ was enough for
my needs. Then, using
issubclass
allowed me to find the correct object I was looking for.
Let us take an example based on the following plugin:
from framework.plugin.plugins import ActivePlugin class SkipfishUnauthPlugin(ActivePlugin): """Active Vulnerability Scanning without credentials via Skipfish.""" RESOURCES = 'Skipfish_Unauth'
OWTF's classful plugin system will retrieve the SkipfishUnauthPlugin class
using the following snippet:
from framework.plugin.plugins import AbstractPlugin class_name = [] plugin_instance = [] # The plugin_module is the dynamic module loaded by imp. for key, obj in plugin_module.__dict__.items(): try: if (issubclass(obj, AbstractPlugin) and obj.__module__ in pathname): class_name.append(key) plugin_instance.append(obj) except TypeError: # The current dict value is not an object. pass
Since a plugin module file is light (i.e. each plugin contains a small amount
of function, variables, etc.), iterating over its attributes is quick. Then,
OWTF retrieves the SkipfishUnauthPlugin class because it is the only one that
inherits from AbstractPlugin. The additional test line 8 ensure that the
current class found is not the ActivePlugin imported line 1 in the previous
snippet.
If you wonder why I have two lists to save the only class from the plugin file, it is just a precaution that I took. That way an user may declare two classes inside one plugin file and OWTF will only retrieve the latest one.
Finally, using both the module reference and the class name of the plugin, OWTF can easily run it like below:
def RunPlugin(self, plugin_dir, plugin, save_output=True): plugin_path = self.GetPluginFullPath(plugin_dir, plugin) (path, name) = os.path.split(plugin_path) plugin_output = None plugin_module = self.GetModule('', name, path + '/') # Create an instance of the plugin class plugin_instance = plugin_module.__dict__[ json.loads(plugin['attr'])['classname']]( self.Core, plugin) # Run the plugin return plugin_instance.run()
Retro compatibility
At that point, the system was working well. I have driven a couple of tests and I did not see any weird behaviors. Then, I thought it could be nice to have both systems working together.
I ensured the retro-compatibility thanks to the class_name key of a plugin.
When loading a plugin, if no class has been found, its value is set to None.
Then, when trying to instantiate the class, if a KeyError is raised, I fall
back on the older system.
Here is the modification:
# If no class has been found, try the old fashioned way. if not plugin_instance: attr = {'classname': None} try: attr.update(plugin_module.ATTR) except AttributeError: pass try: description = plugin_module.DESCRIPTION except AttributeError: description = '' else: # Keep in mind that a plugin SHOULD NOT have more than one # class. The default behaviour is to save the last found. class_name = class_name[-1] plugin_instance = plugin_instance[-1] attr = {'classname': class_name} try: # Did the plugin define an attr dict? attr.update(plugin_instance.ATTR) except AttributeError: pass try: description = plugin_instance.__doc__ except AttributeError: description = '' attr = json.dumps(attr) # Save the plugin into the database # [. . .]
And when trying to run the plugin:
# First try to find the class of the plugin (newest). try: # Create an instance of the plugin class plugin_instance = plugin_module.__dict__[ json.loads(plugin['attr'])['classname']]( self.Core, plugin) # Run the plugin plugin_output = plugin_instance.run() except KeyError: # Second try to find the old fashioned way. try: self.Core.log( 'WARNING: Running the plugin ' + plugin_path + ' the old fashioned way.') plugin_output = plugin_module.run(self.Core, plugin) except AttributeError: pass
:)
Now let's start talking about the real GSoC project: the automated ranking system.
PTP, my solution
I have to implement an automated ranking system for OWTF and so far, the work I have presented does nothing about that but PTP fixes that problem!
PTP is a standalone library that aims to parse the outputs of all pentester's tools. By all I mean it is the final goal of the project.
That way, OWTF will use PTP in order to retrieve the ranking values of each of its plugins.
The origins of the idea
My GSoC proposal did not say anything about a standalone library. That is because the idea came up after discussing with Dan Cornell who works on the ThreadFix project which already provides such feature.
I asked him a couple of questions about how complete ThreadFix's parsing is, what were the difficulties it encountered, etc.
He told me that about the main problem that is keeping up to date on each tool.
The fact is that the vendors might change the output format of the reports from
a version to another. Therefore he thought it could be a stronger approach to
develop a standalone library.
With a standalone library, it will limit the collateral effects. Plus, it will allow a dedicated unit testing framework. In brief, a stronger project.
Internal structure
Now, the PTP library is organized according to the following scheme:
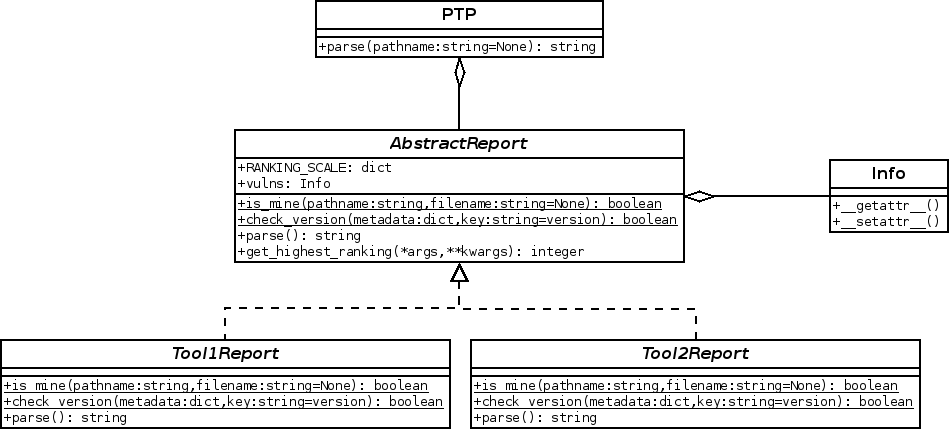
First of all, PTP defines the
Info class that aims to represent any report.
In order to achieve such modularity, it inherits from python's dict object.
Here is how the Info class is defined:
class Info(dict): """Representation of a result from a report provided by a pentesting tool. + name: the name of the vulnerability + ranking: the ranking of the vulnerability. + description: the description of the vulnerability. + kwargs: any key/value attributes the vuln might contain """ __getattr__= dict.__getitem__ __setattr__= dict.__setitem__ __delattr__= dict.__delitem__ def __init__(self, name=None, ranking=None, description=None, **kwargs): """Self-explanatory.""" self.name = name self.ranking = ranking self.description = description for key, value in kwargs.items(): self[key] = value
Each issue from the report must have at least a name, a ranking value and a description. Any other information will be automatically added to the class (like a CVSS link to the issue for instance).
Then the
AbstractReport
class aggregates a list of Info classes. It also defines the basic behavior
of a report such as
is_mine,
get_highest_ranking
and parse
methods.
A quick word on the second one. This method has been implemented mostly for
OWTF which needs to know the highest ranking value of a report in order to rank
the plugins' outputs. Thanks to the RANKING_SCALE defined by the report, it
has an homogeneous scale for rating the issues.
Here is an example of scale that homogenizes the scale from Skipfish with the one from PTP:
HIGH = 4 MEDIUM = 3 LOW = 2 WARNINGS = 1 INFO = 0 # Convert the Skipfish's ranking scale to an unified one. RANKING_SCALE = { HIGH: constants.HIGH, MEDIUM: constants.MEDIUM, LOW: constants.LOW, WARNINGS: constants.INFO, INFO: constants.INFO}
Then for each tool PTP supports, a new class is defined, inheriting from that
abstract class. It purpose is to specifically redefine the is_mine and
parse methods to work with the specificities of the tool.
For instance, Arachni has the following is_mine function:
@classmethod def is_mine(cls, pathname, filename='*.xml'): """Check if it is a Arachni report and if I can handle it. Return True if it is mine, False otherwise. """ fullpath = cls._recursive_find(pathname, filename) if not fullpath: return False fullpath = fullpath[0] # Only keep the first file. if not fullpath.endswith('.xml'): return False try: root = etree.parse(fullpath).getroot() except LxmlError: # Not a valid XML file. return False return cls._is_arachni(root) @classmethod def _is_arachni(cls, xml_report): """Check if the xml_report comes from Arachni. Returns True if it is from Arachni, False otherwise. """ if not cls.__tool__ in xml_report.tag: return False return True
For tools that do not rank their discoveries, PTP uses a dictionary that acts
as a database.
It is the case with Wapiti since it does not
rank its discoveries:
# TODO: Complete the signatures database. SIGNATURES = { # High ranked vulnerabilities 'SQL Injection': HIGH, 'Blind SQL Injection': HIGH, 'Command execution': HIGH, # Medium ranked vulnerabilities 'Htaccess Bypass': MEDIUM, 'Cross Site Scripting': MEDIUM, 'CRLF Injection': MEDIUM, # Low ranked vulnerabilities 'File Handling': LOW, # a.k.a Path or Directory listing 'Resource consumption': LOW, # Informational ranked vulnerabilities 'Backup file': INFO, 'Potentially dangerous file': INFO, 'Internal Server Error': INFO, }
Then PTP checks if the issue from the report exists in the dictionary and it retrieves the corresponding risk:
class WapitiReport(AbstractReport): """Retrieve the information of an wapiti report.""" # [. . .] def parse_xml_report(self): """Retrieve the results from the report.""" vulns = self.root.find('.//vulnerabilities') for vuln in vulns.findall('.//vulnerability'): vuln_signature = vuln.get('name') vuln_description = vuln.find('.//description') if vuln_signature in SIGNATURES: info = Info( name=vuln_signature, ranking=SIGNATURES[vuln_signature], description=vuln_description.text.strip(' \n'), ) self.vulns.append(info)
Last, the PTP class
acts as a python decorator. Its only job is to offer an unique way to use the
library.
When calling its parse method, you are actually calling the parse method of
a report of a specific tool (hence my term of decorator).
The PTP class has the ability to auto-detect the tool from which the report
has been generated. In order to find the correct tool, it calls the is_mine
function of each tool's reports it supports.
class PTP(object): """PTP class definition. Usage: ptp = PTP() ptp.parse(path_to_report) """ # Reports for supported tools. supported = { 'arachni': ArachniReport, 'skipfish': SkipfishReport, 'w3af': W3AFReport, 'wapiti': WapitiReport } def __init__(self, tool_name=None): self.tool_name = tool_name self.report = None def parse(self, pathname=None): if self.tool_name is None: for tool in self.supported.values(): if tool.is_mine(pathname): self.report = tool() break else: try: self.report = self.supported[self.tool_name]() except KeyError: pass if self.report is None: raise NotSupportedToolError('This tool is not supported by PTP.') return self.report.parse(pathname)
As you can see, the user can specify the tool via a string when instancing the class.
An example on how to use the library:
>>> from ptp import PTP >>> ptp = PTP() # Init PTP in auto-detect mode. >>> ptp.parse(path_to_report='path/to/the/report/directory') # [. . .] >>> print(ptp.get_highest_ranking()) 0 # 0 means that the highest know severity is HIGH
What I would like to change
Later I would like to update PTP's internal structure since each tool will have
to support different output formats and different versions.
That is why I wish to change its structure to something similar to the
following:
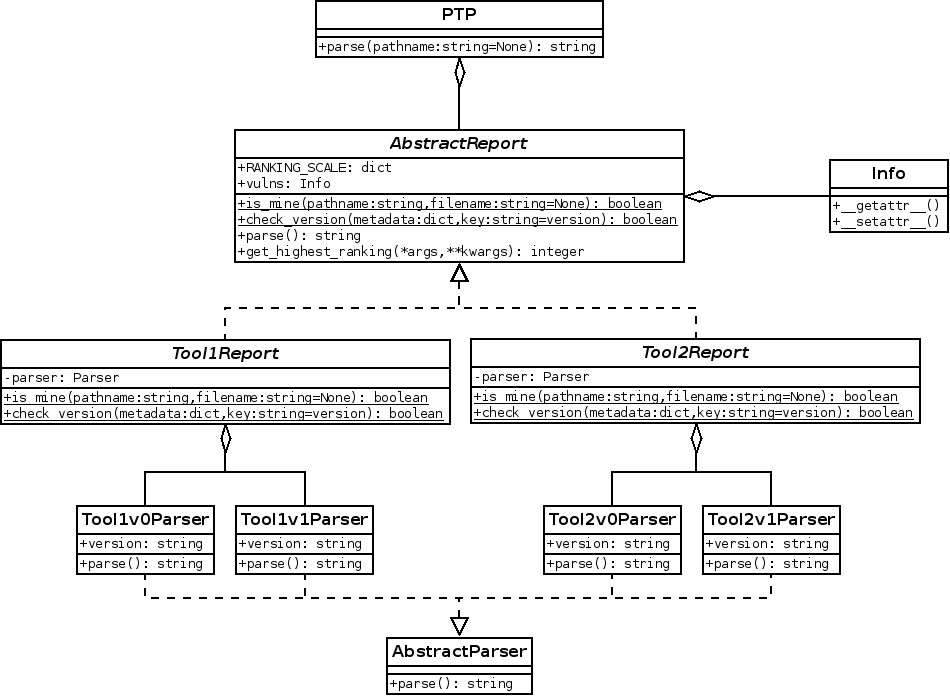
With this new structure, a report will not be dependent anymore on the output format, nor the version of the tool. It will instantiate different parsing methods that will take care of these problems.
Current state of development
At this moment, PTP is more a proof of concept than a completely stable/finished project.
To be precise, PTP only supports four different tools (Arachni, Skipfish, W3AF and Wapiti) and the parsing methods were only tested for one version of each tool.
Plus, it only retrieves basic information of each issue. I decided to develop the library that way because I needed to focus the early development in order to have quick results for OWTF.
The master branch of the project is considered as stable and any further modification will be done on the develop one. Since PTP is reused by OWTF, I will have better stability for my project that way.
Integration of PTP to OWTF
In order to have OWTF using PTP, I had to integrate the library. I managed to succeed thanks to the following changes.
First, I needed to update the poutput_manager of OWTF in order to specify the
owtf_rank value:
def SavePluginOutput(self,
plugin,
output,
duration,
- target=None):
+ target=None,
+ owtf_rank=None):
"""Save into the database the command output of the plugin `plugin."""
session = self.Core.DB.Target.GetOutputDBSession(target)
session = session()
session.merge(models.PluginOutput(
key = plugin["key"],
plugin_code = plugin["code"],
plugin_group = plugin["group"],
plugin_type = plugin["type"],
output = json.dumps(output),
start_time = plugin["start"],
end_time = plugin["end"],
execution_time = duration,
status = plugin["status"],
- output_path = plugin["output_path"])
+ output_path = plugin["output_path"],
+ owtf_rank=owtf_rank)
+ )
session.commit()
session.close()
Then I had to change a few things in the plugin_handler's ProcessPlugin
function:
def ProcessPlugin(self, plugin_dir, plugin, status={}):
# [. . .]
try:
output = self.RunPlugin(plugin_dir, plugin)
plugin['status'] = 'Successful'
plugin['end'] = self.Core.Timer.GetEndDateTimeAsStr('Plugin')
+ owtf_rank = None
+ try:
+ parser = PTP()
+ parser.parse(pathname=plugin['output_path'])
+ owtf_rank = 3 - parser.get_highest_ranking()
+ except PTPError: # Not supported tool or report not found.
+ pass
status['SomeSuccessful'] = True
self.Core.DB.POutput.SavePluginOutput(
plugin,
output,
- self.Core.Timer.GetElapsedTimeAsStr('Plugin'))
+ self.Core.Timer.GetElapsedTimeAsStr('Plugin'),
+ owtf_rank=owtf_rank)
return output
except KeyboardInterrupt:
# [. . .]
And that is all! I thought the integration would have taken more time but it was in fact quite easy.
User-friendly display of the rankings
So far so good. In a couple of weeks, I have managed to create a standalone library that is my solution for the automated ranking system. It has been successfully integrated but I still had to update the template of the plugin report.
The older version of the template
Before describing my modification, I show you the previous template:
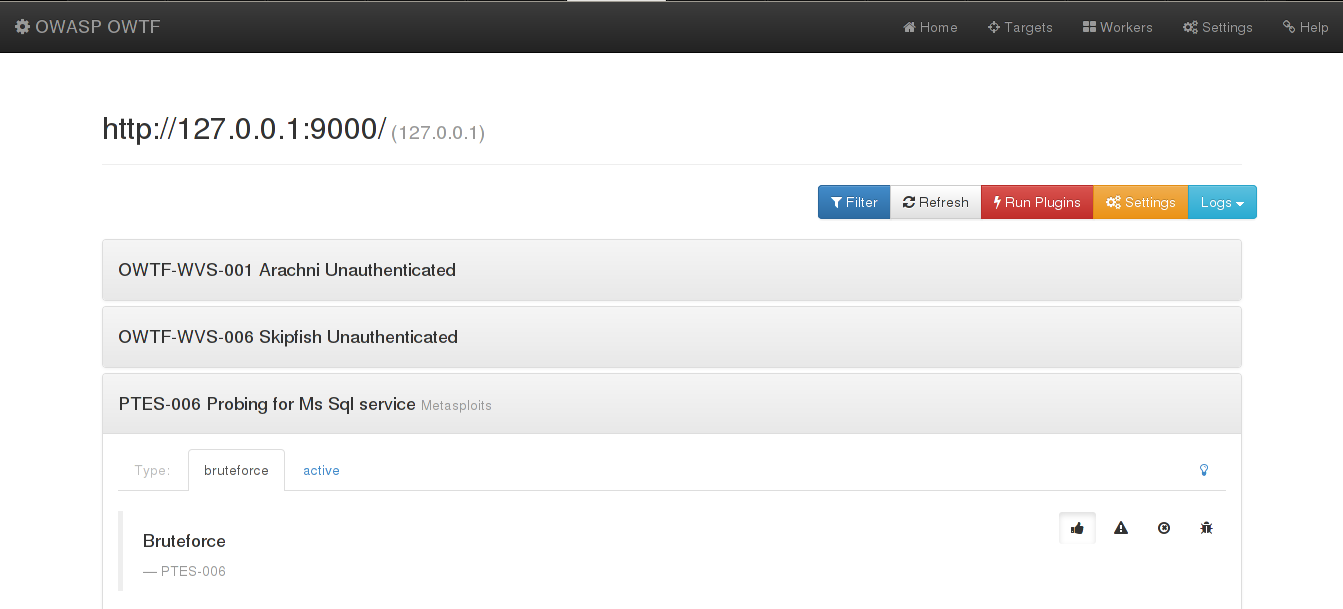
As you can see, nothing is there to help the user to focus on the seemingly weakest spots of the tested application.
The modification
In order to help the user, OWTF needed a template where each automated ranking value would appear. The system would be hierarchical following these rules:
- A ranking is set for a plugin's output.
- The maximum ranking values from the plugins' outputs is assigned to a test case (note, a test case is a group of a plugin's outputs since a plugin can be passive, active, external, semi-passive, etc.).
- The maximum ranking values from the test cases is assigned to the report.
- If the ranking value is from OWTF then it has to be highlighted as such.
These simple rules implied a much more complex problem. The ranking value of the report and a test case might be changed if only one plugin's output is re-ranked.
That means I had to implement a template where the ranking values would be automatically updated when first the page was loaded and second when a ranking was overridden by the user.
First I decided to create a local copy of the plugins' outputs. I made that
decision in order to optimize the rendering system.
By having a local copy, it will not be required to call the OWTF's api in
order to retrieve the outputs each time the user changes a ranking.
/* Global copy of the plugins' outputs in order to avoid calling the API each * time the user changes a rank. */ var copyPOutputs = {};
Most of that time was spent debugging why such function was not called, why
such switch test was not working, etc.
For example, in order to update the labels when loading the page, I wrote a
function that is called when the document is ready.
With JQuery, the syntax is the following:
/* This function is called as soon as the document is ready. */ $(function() { /* Do something. */ });
When I wrote my code, some functions were not called and I still don't understand why:
$(function() { var req = $.getJSON(pluginSpace.poutput_api_url, function(data) { /* Global copy of the POutputs. */ for (var i = 0; i < data.length; i++) { if (!copyPOutputs[data[i].plugin_code]) copyPOutputs[data[i].plugin_code] = {}; copyPOutputs[data[i].plugin_code][data[i].plugin_type] = data[i]; } }); /* Update every colors. */ updateTargetInfo(); /* Never called. */ updateAllTestCasesInfo(); /* Never called. */ });
But that version worked like a charm:
$(function() {
var req = $.getJSON(pluginSpace.poutput_api_url, function(data) {
/* Global copy of the POutputs. */
for (var i = 0; i < data.length; i++) {
if (!copyPOutputs[data[i].plugin_code])
copyPOutputs[data[i].plugin_code] = {};
copyPOutputs[data[i].plugin_code][data[i].plugin_type] = data[i];
}
});
/* Update every colors. */
+ req.complete(function() {
updateTargetInfo();
updateAllTestCasesInfo();
+ });
});
In the second version (the one working), I used the
.complete() function. Using that,
I force the calls of both updateTargetInfo() and updateAllTestCasesInfo as
soon as the request is completed.
Note: the complete() function is deprecated since JQuery 1.8. always()
should be used instead.
My question is why these functions were not called in the first version? Mystery.
The new version
After all these modification, OWTF has now a nicer template:
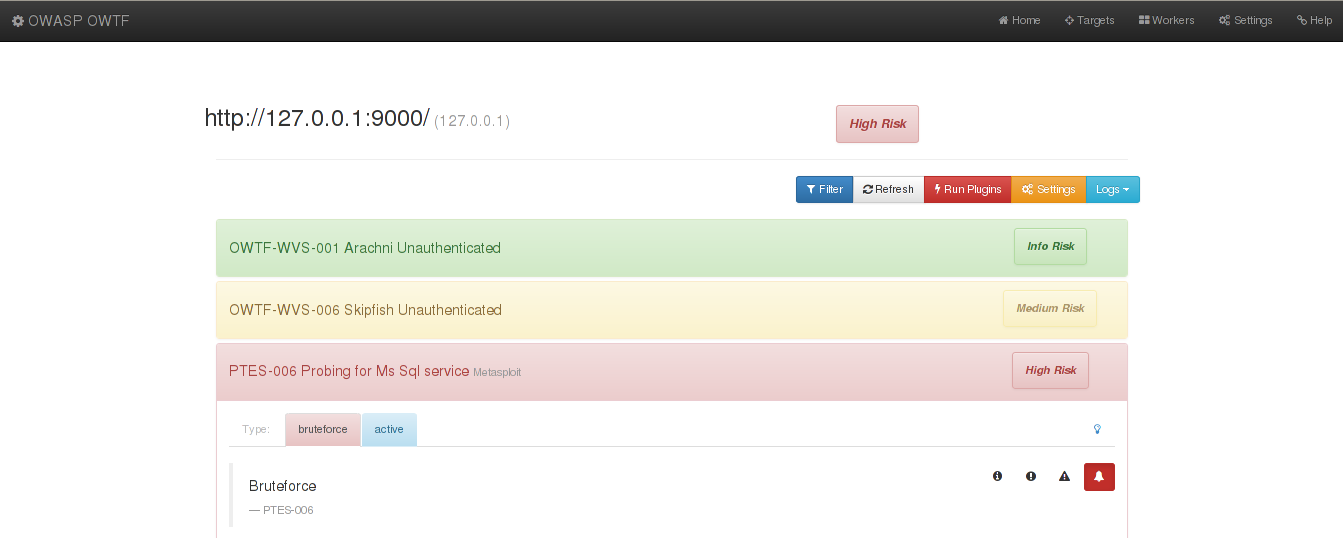
Now the user can quickly see what spots he should check first. Then he might override the ranking value as he wish, therefore creating the final ranking values of the test.
The automated ranking values are highlighted using the
opacity css
attribute as shown in the Skipfish test case.
All in all, it took me around 8 + 4 straight hours of work to achieve the last render (plus a couple of modification when I had the feedbacks). This is a lot for such small graphical changes but JQuery is really tricky (especially when you never ever wrote any line of JS).
Conclusion
Wow, finally! That took longer to present than I expected.
The past four weeks were kind of full. I worked a lot on my project and I am really proud to see that most of the painful work has been done.
I looked at my proposal and I saw that I managed to almost finished the Stage 1 and Stage 3:
- PTP retrieves the ranking values from different tools
- The plugin report template has been updated in order to graphically display the ranking values retrieved by PTP.
- It works!
Of course, the Stage 2 will take a lot of time. It concerns the supported tools for PTP. For now, PTP only supports four tools where OWTF uses way more but since I have a working PoC, I think it will be easy to support the other tools.
Plus, my proposal also presents aside projects that I would like to do but only if I have time by the end of my main project.
With my exams coming soon, I will focus on my studies for the next couple of weeks but I hope to have something interesting for the third monthly post :)