The third month of GSoC 2014 is now over. Sadly I had a lot of exams these last couple of weeks (school projects, oral presentations, theoretical exams, etc.) which means that this post will be brief.
Nevertheless, I managed to enhance PTP's architecture and I think this could be interesting. I also completed the documentation of the project using Sphinx not that anyone cares.
Thought on PTP's architecture
The limits of the previous architecture
As you may have read in my previous post about my GSoC project, I found that the previous PTP's architecture would be hard to maintain as the project would grow.
Below is the previous architecture:
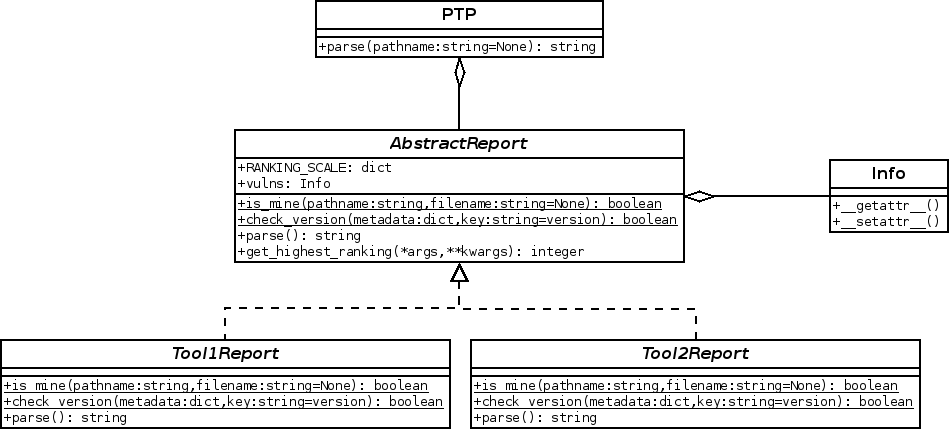
Since the report and the parser of one tool are defined in a unique class, the more PTP would have to support different versions and report formats of a same tool, the harder it would become to have a clean and stable code.
That is why I thought it would be better for PTP to follow a new architecture in which the report and the parsing functions would be split into two distinct classes like in the following diagram:
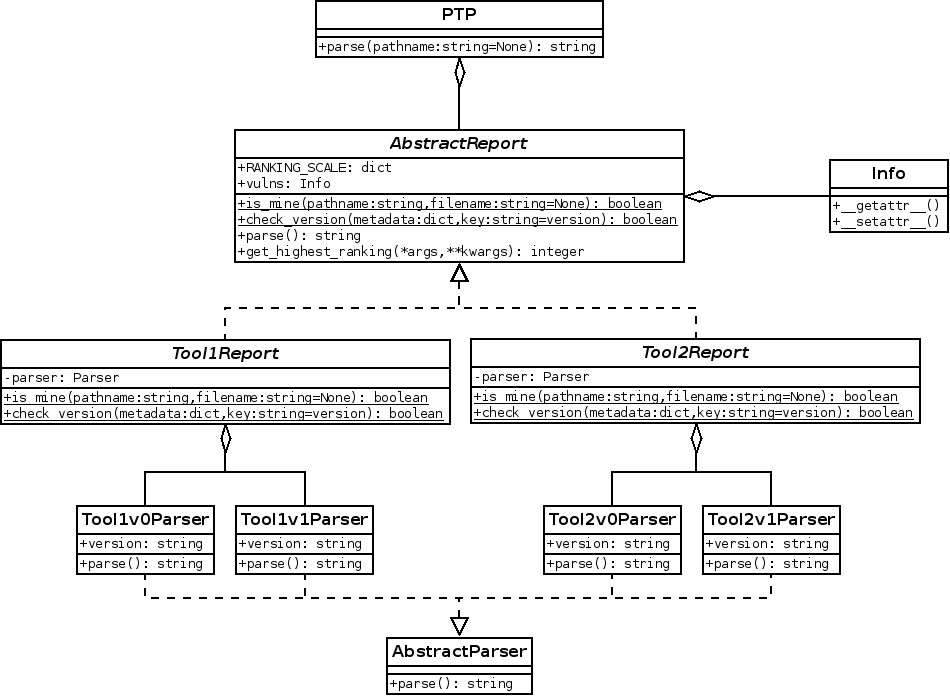
When implementing such architecture, I thought it would be even better to factorize the code dealing with the opening/closing of the report files into another layer. Therefore, each parser dealing with a XML report would inherit from a specialized XML abstract parser class. The same for JSON, HTML. etc.
PTP's new architecture
First, PTP's supports was not enhanced at all. It still supports only four different tools (and only a specific version of these tools).
But I think that with the new architecture I implemented, it will be easier for me to add new supports, which is the main mission for the next month ;)
Anyway, PTP's new architecture implements the different extra layers I presented in the previous post, plus the one in the previous section.
The complete architecture is shown below:
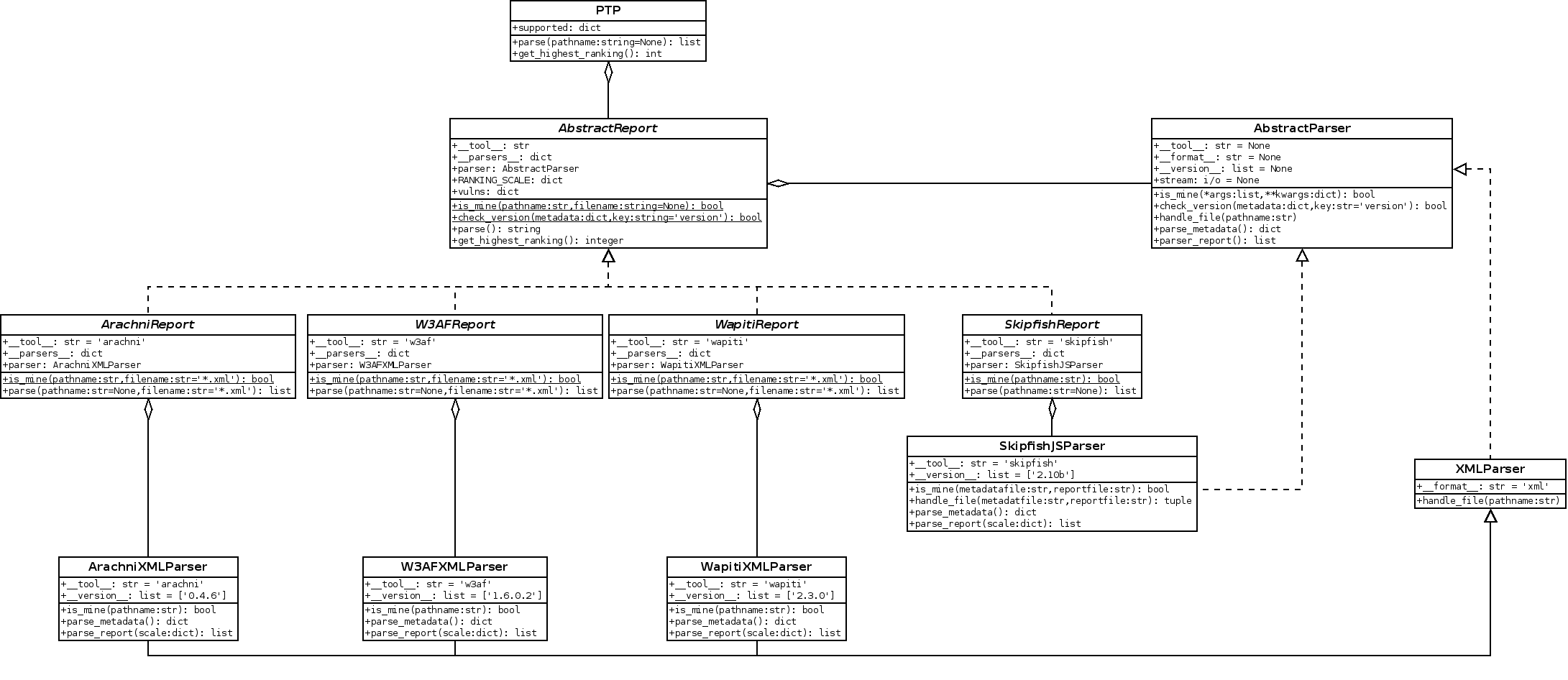
With the AbstractReport class comes the AbstractParser one. The functions
like is_mine and check_version have been moved to the parser. They still
exist in the report but now act as proxy-functions for their siblings.
The AbtractParser defines a new function, handle_file, which creates a
stream on the report data. I use the word stream because it might be
anything, from some XML handles to list containing each line of the report.
Of course, since AbstractParser is an abstract layer and handle_file is a
specialized function, it has to be overridden.
Speaking about XML, I implemented a XMLParser class that overrides the
handle_file abstract function:
class XMLParser(AbstractParser): """Specialized parser for XML formatted report.""" #: str -- XMLParser only supports XML files. __format__ = 'xml' def __init__(self, pathname): """Initialize XMLParser. :param str pathname: path to the report file. """ AbstractParser.__init__(self, pathname) @classmethod def handle_file(cls, pathname): """Specialized file handler for XML files. :param str pathname: path to the report file. :raises ValueError: if the report file has not the right extension. :raises LxmlError: if Lxml cannot parse the XML file. """ if not pathname.endswith(cls.__format__): raise ValueError( "This parser only supports '%s' files" % cls.__format__) return etree.parse(pathname).getroot()
As you can see, in this context, a stream is a lxml tree object.
I have an exception for Skipfish because its parsing is unique.
Instead of having one report file, it generates a tree structure of directories. The simplest way I found to retrieve the ranking values is to only read the issue_samples file.
But this file is a js one and I had to write an ugly hack to read it. That is why there is no specialized parser class between the abstract and the Skipfish ones.
Simplification
Useless Info class
Apart from the modification of the architecture, I tried to have a honest look on the current implementation of PTP. I was trying to answer question like Is this pertinent?, Is it mandatory to have this?, Could it be simpler?, etc.
I read a couple of articles about python, what to do, what to avoid, and I stumbled on a conference about the classes and how often we could avoid them.
Then I took a look at my Info
class
and realized that it was exactly a case shown in the video.
Jack Diederich explains that instead of writing a class that inherits from a
standard python type (dict in my case) because maybe it might offer something
more later, I should use the standard type instead and implement that class
when I will need it.
Therefore I removed the Info class, which was in fact just a dictionary, and
replaced each occurrence by a simple dict.
Use iterators whenever possible
Also, I realized that I was using copy-based functions too often.
For instance, in python 2.x, I used the dict.values when looping over the
dictionary values. But before python 3.x, this function creates a copy of the
values before iterating over them, which can become memory inefficient when
dealing with big dictionaries.
Therefore, I replaced each function of this kind with its iterator version
(e.g. values to itervalues).
But since python 3.x, this has been modified and functions like itervalues
have been moved to values (i.e. the default values function's behavior is
to generate iterators and not to copy the values anymore).
So, in order to keep the compatibility between 2.x and 3.x and force the use of iterators, I modified PTP's code to wisely decide which one to use.
This wisdom is given by the following snippet for instance:
@classmethod def check_version(cls, metadata, key='version'): """Checks the version from the metadata against the supported ones. :param dct metadata: The metadata in which to find the version. :param str key: The :attr:`metadata` key containing the version value. :return: `True` if it support that version, `False` otherwise. :rtype: :class:`bool` """ try: parsers = cls.__parsers__.itervalues() except AttributeError: # Python3 then. parsers = cls.__parsers__.values() if metadata[key] in parsers: return True return False
Documentation using sphinx
The last point I worked on during this month is creating the documentation for PTP.
A couple of weeks earlier, I discussed the fact that OWTF should use a tool that automatically generates the documentation from the docstrings. We were hesitating between doxygen and sphinx.
Since I already used doxygen in other projects, I thought I could use sphinx for PTP as a beta test, before deciding which one to use in OWTF.
Therefore I spent a day or two writing the full technical documentation for PTP, as you may have guessed based on the snippets I presented in this post.
I was glad to see that the configuration of sphinx for a project is pretty easy and the syntax is really simple but so is doxygen. For now, I think both are equals and this beta test did not give me enough elements to decide on which one to use for OWTF.
Another point I would like to briefly discussed is that I really want to have something clean for PTP. It is for now the cleanest project I have created in my opinion and I want to keep it as clean as possible.
That is why, after a friend of mine linked me the repository of SyncThing, which is one of the cleanest repo I have ever see, I decided to follow the same release system as it uses. The release I have pushed and every next ones will therefore follow the Semantic Versioning Guidelines
Conclusion
I cannot really conclude on anything after this month. With my exams I did not really have a lot of free times to fully work on my GSoC project.
Nevertheless I managed to updated PTP's architecture like I aimed to do in my previous post. I feel confident about the robustness of the new one and I think that it will ease any further work.
Also I simplified the code base and ensured the inter-compatibility between python 2.x and 3.x versions and I was able to configure sphinx and write the technical documentation of the project.
I hope I will have more to say for the next monthly GSoC post :)